Built-in Models: STEVE-1#
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft
Quick Facts
STEVE-1 [1] finetunes VPT to follow short-horizon open-ended text and visual instructions without the need of costly human annotations.
Insights#
Pre-trained foundation models demonstrates suprising ability to be efficiently fine-tuned for becoming instruction-following. In sequential decision-making domains, two foundation models in Minecraft are released: VPT [2] and MineCLIP [3], opening intriguing possibilities for exploring the finetuning of instruction-awared decision-making agents.
The authors draw insights from unCLIP [4] to propose a two-stage learning framework for training STEVE-1, eliminating laborious human annotations.
Method#
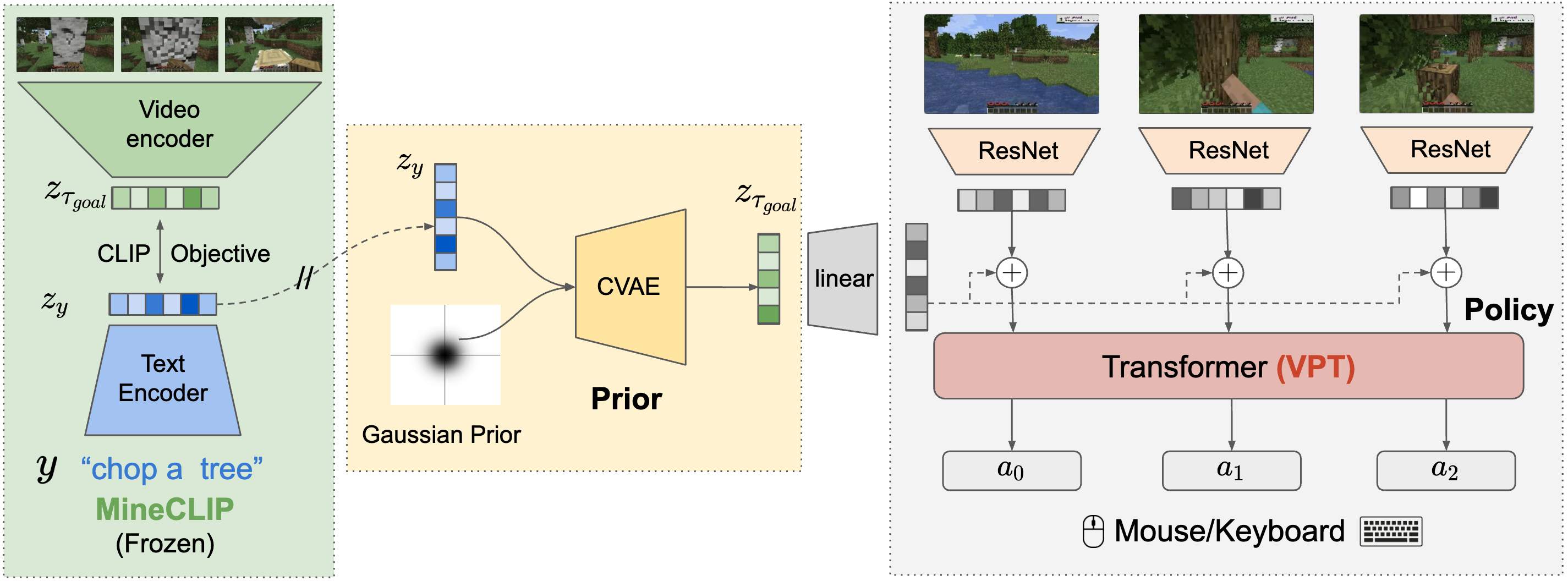
To create a policy in Minecraft conditioned text instructions \(y\), they ultilize a dataset of (partially) annotated trajectories \([(\tau_1, y_1), (\tau_2, y_2), \dots, (\tau_n, \emptyset)]\) They employ MineCLIP which is capable of generating aligned latents \(z_{\tau_{t:t+16}}\) and \(z_y\), where \(z_{\tau_{\text{goal}}} = z_{\tau_{t:t+16}}\) is an embedding of 16 consecutive frames.
The instruction-following model is composed of a policy and a prior:
where the policy generates a trajectory \(\tau\) conditioned on the aligned latents \(z_{\tau_{\text{goal}}}\) and the prior generates \(z_{\tau_{\text{goal}}}\) conditioned on the instruction \(y\).
To train the policy, they use a modification of hindsight relabeling to generate goals for each trajectory:

They randomly select timesteps from episodes and use hindsight relabeling to set the intermediate goals for the trajectory segments to those visual MineCLIP embeddings. Image credit: [1]#
By finetuning VPT on this dataset, the policy learns to reach given goal states (visual goals).
To also learn to follow text instructions, they train a conditioned variational autoencoder (CVAE) with Gaussian prior and posterior to translate from a text embedding \(z_y\) to a visual embedding \(z_{\tau_{\text{goal}}}\). The training objective is a standard ELBO loss:
They ultilize classifier-free guidance to train the policy, where the goal embedding is occasionally droped out during training. During inference, they compute a combination of logits with and without combination to generate the final trajectory.