Data#
We design a trajectory structure for storing Minecraft data. Based on this data structure, users are able to store and retrieve arbitray trajectory segment in an efficient way.
MineStudio Data
Quick Start#
Here is a minimal example to show how we load trajectories from the dataset.
from minestudio.data import RawDataset
from minestudio.data.minecraft.callbacks import ImageKernelCallback, ActionKernelCallback
dataset = RawDataset(
dataset_dirs=[
'/nfs-shared-2/data/contractors/dataset_6xx',
'/nfs-shared-2/data/contractors/dataset_7xx',
'/nfs-shared-2/data/contractors/dataset_8xx',
'/nfs-shared-2/data/contractors/dataset_9xx',
'/nfs-shared-2/data/contractors/dataset_10xx',
],
modal_kernel_callbacks=[
ImageKernelCallback(frame_width=224, frame_height=224, enable_video_aug=False),
ActionKernelCallback(enable_prev_action=True, win_bias=1, read_bias=-1),
],
win_len=128,
split_ratio=0.9,
shuffle_episodes=True,
)
item = dataset[0]
print(item.keys())
You may see the output like this:
[23:09:38] [Kernel] Modal image load 15738 episodes.
[23:09:38] [Kernel] Modal action load 15823 episodes.
[23:09:38] [Kernel] episodes: 15655, frames: 160495936.
[Raw Dataset] Shuffling episodes with seed 0.
dict_keys(['image', 'image_mask', 'action_mask', 'env_action', 'env_prev_action', 'agent_action', 'agent_prev_action', 'mask', 'text', 'timestamp', 'episode', 'progress'])
Hint
Please note that the dataset_dirs parameter here is a list that can contain multiple dataset directories. In this example, we have loaded five dataset directories.
If an element in the list is one of 6xx, 7xx, 8xx, 9xx, or 10xx, the program will automatically download it from Hugging Face, so please ensure your network connection is stable and you have enough storage space.
If an element in the list is a directory like /nfs-shared/data/contractors/dataset_6xx, the program will load data directly from that directory.
We strongly recommend users to manually download the datasets and place them in a local directory, such as /nfs-shared-2/data/contractors/dataset_6xx, to avoid downloading issues.
Alternatively, you can also load trajectories that have specific events, for example, loading all trajectories that contain the kill entity event.
from minestudio.data import EventDataset
from minestudio.data.minecraft.callbacks import ImageKernelCallback, ActionKernelCallback
dataset = EventDataset(
dataset_dirs=[
'/nfs-shared-2/data/contractors/dataset_6xx',
'/nfs-shared-2/data/contractors/dataset_7xx',
'/nfs-shared-2/data/contractors/dataset_8xx',
'/nfs-shared-2/data/contractors/dataset_9xx',
'/nfs-shared-2/data/contractors/dataset_10xx',
],
modal_kernel_callbacks=[
ImageKernelCallback(frame_width=224, frame_height=224, enable_video_aug=False),
ActionKernelCallback(),
],
win_len=128,
split_ratio=0.9,
event_regex='minecraft.kill_entity:.*',
min_nearby=64,
max_within=1000,
)
print("length of dataset: ", len(dataset))
item = dataset[0]
print(item.keys())
You may see the output like this:
[23:16:07] [Event Kernel Manager] Number of loaded events: 61
[23:16:07] [Kernel] Modal image load 15738 episodes.
[23:16:07] [Kernel] Modal action load 15823 episodes.
[23:16:07] [Kernel] episodes: 15655, frames: 160495936.
[23:16:07] [Event Dataset] Regex: minecraft.kill_entity:.*, Number of events: 61, number of items: 16835.
length of dataset: 16835
dict_keys(['image', 'env_action', 'agent_action', 'mask', 'text', 'episode', 'timestamp'])
Learn more about Event Dataset
We also provide a dataloader wrapper to make it easier to use the dataset.
from minestudio.data import RawDataModule
from minestudio.data.minecraft.callbacks import (
ImageKernelCallback, ActionKernelCallback
)
data_module = RawDataModule(
data_params=dict(
dataset_dirs=[
'/nfs-shared-2/data/contractors/dataset_6xx',
'/nfs-shared-2/data/contractors/dataset_7xx',
'/nfs-shared-2/data/contractors/dataset_8xx',
'/nfs-shared-2/data/contractors/dataset_9xx',
'/nfs-shared-2/data/contractors/dataset_10xx',
],
modal_kernel_callbacks=[
ImageKernelCallback(frame_width=224, frame_height=224, enable_video_aug=False),
ActionKernelCallback(enable_prev_action=True, win_bias=1, read_bias=-1),
],
win_len=128,
split_ratio=0.9,
shuffle_episodes=True,
),
batch_size=3,
num_workers=8,
prefetch_factor=None,
episode_continuous_batch=True,
)
data_module.setup()
loader = data_module.train_dataloader()
for idx, batch in enumerate(loader):
print(
"\t".join(
[f"{a} {b}" for a, b in zip(batch['episode'], batch['progress'])]
)
)
if idx > 10:
break
You may see the output like this:
[23:21:03] [Kernel] Modal image load 15738 episodes.
[23:21:03] [Kernel] Modal action load 15823 episodes.
[23:21:03] [Kernel] episodes: 15655, frames: 160495936.
[Raw Dataset] Shuffling episodes with seed 0.
[23:21:03] [Kernel] Modal image load 15738 episodes.
[23:21:03] [Kernel] Modal action load 15823 episodes.
[23:21:03] [Kernel] episodes: 15655, frames: 160495936.
[Raw Dataset] Shuffling episodes with seed 0.
thirsty-lavender-koala-7552d1728d4d-20220411-092042 0/75 Player63-f153ac423f61-20210723-162533 0/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 0/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 1/75 Player63-f153ac423f61-20210723-162533 1/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 1/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 2/75 Player63-f153ac423f61-20210723-162533 2/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 2/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 3/75 Player63-f153ac423f61-20210723-162533 3/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 3/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 4/75 Player63-f153ac423f61-20210723-162533 4/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 4/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 5/75 Player63-f153ac423f61-20210723-162533 5/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 5/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 6/75 Player63-f153ac423f61-20210723-162533 6/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 6/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 7/75 Player63-f153ac423f61-20210723-162533 7/8 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 7/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 8/75 Player985-f153ac423f61-20210914-114117 0/23 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 8/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 9/75 Player985-f153ac423f61-20210914-114117 1/23 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 9/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 10/75 Player985-f153ac423f61-20210914-114117 2/23 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 10/88
thirsty-lavender-koala-7552d1728d4d-20220411-092042 11/75 Player985-f153ac423f61-20210914-114117 3/23 wiggy-aquamarine-tapir-c09d137a3840-20220318-024035 11/88
Data Structure#
We classify and save the data according to its corresponding modality, with each modality’s data being a sequence over time. Sequences from different modalities can be aligned in chronological order. For example, the “action” modality data stores the mouse and keyboard actions taken at each time step of the trajectory; the “video” modality data stores the observations returned by the environment at each time step of the trajectory.
Note
The data of different modalities is stored independently. The benefits are: (1) Users can selectively read data from different modalities according to their requirements; (2) Users are easily able to add new modalities to the dataset without affecting the existing data.
For the sequence data of each modality, we store it in segments, with each segment having a fixed length (e.g., 32), which facilitates the reading and storage of the data.
Note
For video data, the efficiency of random access is usually low because decoding is required during the reading process. An extreme case would be to save it as individual images, which would allow for high read efficiency but take up a large amount of storage space.
We adopt a compromise solution by saving the video data in video segments, which allows for relatively high read efficiency while not occupying too much storage space. When user wants to read a sequence of continuous frames, we only need to retrieve the corresponding segments and decode them.
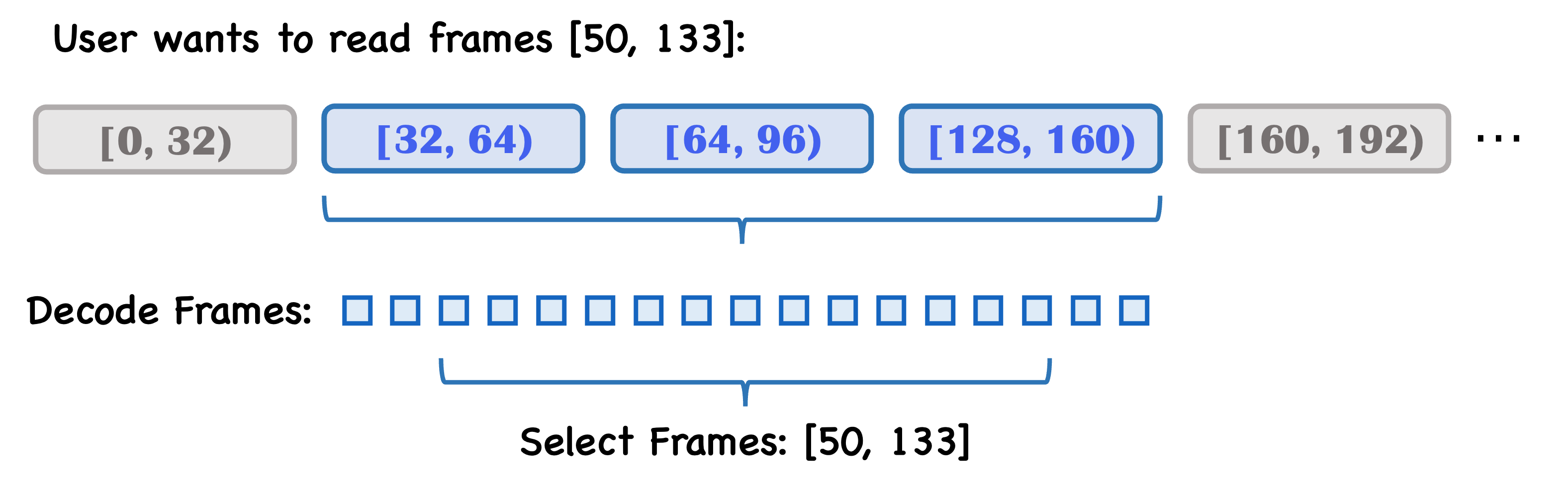
Learn more about the details
Segmented sequence data is stored in individual lmdb files, each of which contains the following metadata:
{
"__num_episodes__": int, # the total number of episodes in this lmdb file
"__num_total_frames__": int, # the total number of frames in this lmdb file
"__chunk_size__": int, # the length of each segment (e.g. 32)
"__chunk_infos__": dict # save the information of the episode part in this lmdb file, e.g. the start and end index, episode name.
}
Once you know the episode name and which segment you want to read, you can identify the corresponding segment bytes in the lmdb file and decode it to get the data.
with lmdb_handler.begin() as txn:
key = str((episode_idx, chunk_id)).encode()
chunk_bytes = txn.get(key)
Hint
In fact, you don’t need to worry about these low-level details, as we have packaged these operations for you. You just need to call the corresponding API. The class primarily responsible for managing these details for a single data modality is minestudio.data.minecraft.core.ModalKernel. For managing multiple modalities, minestudio.data.minecraft.core.KernelManager is used, which internally utilizes ModalKernel instances.
With ModalKernel, you can perform these operations on the data:
Get the list of episodes (trajectories):
# Assuming 'modal_kernel' is an instance of ModalKernel episode_list = modal_kernel.get_episode_list()
Get the total number of frames for specified episodes:
# Assuming 'modal_kernel' is an instance of ModalKernel total_frames = modal_kernel.get_num_frames([ "episode_1", "episode_2", "episode_3" ])
Read a sequence of frames from an episode:
# Assuming 'modal_kernel' is an instance of ModalKernel # and it has been initialized with an appropriate ModalKernelCallback data_dict = modal_kernel.read_frames( eps="episode_1", start=11, # Starting frame index win_len=33, # Window length (number of frames to read) skip_frame=1 # Number of frames to skip between reads (1 means no skip) ) # 'data_dict' will contain the processed frames and potentially other info like a mask, # depending on the ModalKernelCallback.
Note
The processing of data, such as merging chunks, extracting specific information, and padding, is handled by a
ModalKernelCallbackinstance that is provided when theModalKernelis created. This callback is specific to the data modality (e.g., video, actions).
Built-in Modalities#
We provide the following built-in modalities for users to store data:
Modality |
Description |
Data Format |
|---|---|---|
image |
Visual observations from the environment (frames) |
|
action |
Player/agent’s mouse and keyboard inputs |
|
meta_info |
Auxiliary information about the game state/episode |
|
segmentation |
Object segmentation masks for the visual frames |
|
Video and Segmentation Visualization