Built-in Models: GROOT#
Quick Facts
GROOT is an open-world controller that follows open-ended instructions by using reference videos as expressive goal specifications, eliminating the need for text annotations.
GROOT leverages a causal transformer-based encoder-decoder architecture to self-supervise the learning of a structured goal space from gameplay videos.
Insights#
To develop an effective instruction-following controller, defining a robust goal representation is essential. Unlike previous approaches, such as using language descriptions or future images (e.g., Steve-1), GROOT leverages reference videos as goal representations. These gameplay videos serve as a rich and expressive source of information, enabling the agent to learn complex behaviors effectively. The paper frames the learning process as future state prediction, allowing the agent to follow demonstrations seamlessly.
Method#
Formally, the future state prediction problem is defined as maximizing the log-likelihood of future states given past ones: :math:log p_{theta}(s_{t+1:T} | s_{0:t}). By introducing \(g\) as a latent variable conditioned on past states, the evidence lower bound (ELBO) can be expressed as:
where \(D_{\text{KL}}\) is the Kullback-Leibler divergence, and \(q_\phi\) represents the variational posterior.
This objective can be further simplified using the transition function \(p_{\theta}(s_{t+1}|s_{0:t},a_t)\) and a goal-conditioned policy (to be learned) \(\pi_{\theta}(a_t|s_{0:t},g)\):
where \(q_\phi(\cdot|s_{0:T})\) is implemented as a video encoder, and \(p_{\theta}(\cdot|s_{0:\tau+1})\) represents the Inverse Dynamic Model (IDM), which predicts actions to transition to the next state and is typically a pretrained model. Please refer to the paper for more details.
Architecture#
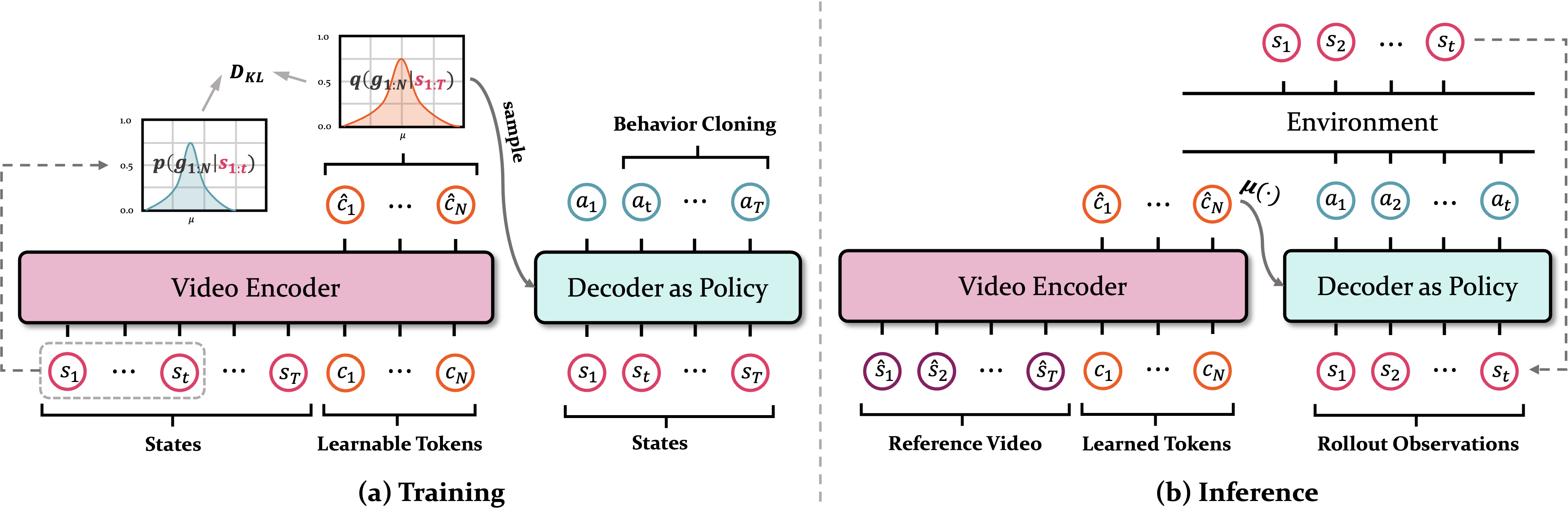
GROOT agent architecture.#
The GROOT agent consists of a video encoder and a policy decoder. The video encoder is a non-causal transformer that extracts semantic information and generates goal embeddings. The policy is a causal transformer decoder that receives the goal embeddings as the instruction and autoregressively translates the state sequence into a sequence of actions.
For more details, a vision backbone is used to extract features from the video frames, which are then fed into the transformer encoder. The non-causal transformer outputs a set of summary tokens \(\{\hat{c}_{1:N}\}\), which are used to sample a set of embeddings \(\{g_{1:N}\}\) using the reparameterization trick: \(g_t \sim \mathcal{N}(\mu(\hat{c}_t), \sigma(\hat{c}_t))\). The decoder then takes the goal embeddings and the state sequence as input and autoregressively predicts the action sequence. To see a detailed architecture, please refer to the paper. and the official repository.
Our Implementation#
Our implementation of GROOT mainly consists of 5 components: LatentSpace, VideoEncoder, ImageEncoder, Decoder, and GrootPolicy in minestudio/models/groot_one/body.py.
Click to see the arguments for each component of GROOT
Argument Name |
Description |
Component Type |
|---|---|---|
|
The dimension of the hidden state. |
All components |
|
The number of spatial layers in the pooling transformer. |
|
|
The number of temporal layers in the video encoder. |
|
|
The number of heads in the multi-head attention. |
|
|
The dropout rate. |
|
|
The number of layers in the transformer. |
|
|
The number of timesteps for an input sequence. |
|
|
The memory length for the Transformer XL. |
|
|
The vision backbone for feature extraction. |
|
|
Whether to freeze the backbone weights. |
|
|
The keyword arguments for the video encoder. |
|
|
The keyword arguments for the image encoder. |
|
|
The keyword arguments for the decoder. |
|
|
The action space for the environment. |
|
Here we provide a brief overview and workflow of the components:
Click to see the workflow of GROOT
The
forwardmethod of GrootPolicy takes argumentsinput: Dictandmemory: Optional[List[torch.Tensor]] = None.The
input['image`]firstly get rearranged and transformed forself.backbone. Then image features are extracted using the backbone and get updimensioned.If
referenceis in the input, which means a demonstration video is provided, the reference video is encoded the same way as the input image. Otherwise, reference video is the input sequence itself for self-supervised learning.The posterior distribution is calculated using the video encoder, and the goal embeddings are sampled.
The prior distribution is calculated using the image encoder with only the first frame.
The image features and goal embeddings are concatenated and fused to form the input for the decoder.
The decoder autoregressively predicts the action logits as well as generates next memory.
Training GROOT#
To implement the training objective of GROOT, we add a kl_divergence callback in minestudio/train/mine_callbacks. This callback calculates the KL divergence between the posterior and prior distributions and adds it to the loss.
To train GROOT, we provide a configuration file minestudio/tutorials/train/3_pretrain_groots/groot_config.yaml.
Specify this file path with hydra to start training:
cd minestudio/tutorials/train/3_pretrain_groots
python main.py
Evaluation#
Here is an example of how to evaluate the trained GROOT model. Provide it with a reference video and let it run!
from minestudio.simulator import MinecraftSim
from minestudio.simulator.callbacks import RecordCallback, SpeedTestCallback
from minestudio.models import GrootPolicy, load_groot_policy
import numpy as np
import av
if __name__ == '__main__':
policy = load_groot_policy(
ckpt_path = # specify the checkpoint path here,
).to("cuda")
resolution = (224, 224) # specify the observation size
env = MinecraftSim(
obs_size = resolution,
preferred_spawn_biome = "forest",
callbacks = [
RecordCallback(record_path = "./output", fps = 30, frame_type="pov"),
SpeedTestCallback(50),
]
)
ref_video_path = # specify the reference video path here
memory = None
obs, info = env.reset()
obs["ref_video_path"] = ref_video_path
for i in range(1200):
action, memory = policy.get_action(obs, memory, input_shape='*')
obs, reward, terminated, truncated, info = env.step(action)
env.close()
Note
We provide a set of reference videos in huggingface.
An example of inference code using our framework can be found in Tutorial: Inference with GROOT.