Event Dataset#
The Event Dataset provides a way to load data segments centered around specific in-game events. This is useful for training models that need to react to or learn from particular occurrences. The underlying EventDataset class works by identifying events (e.g., kill_entity, mine_block) from an event database and then fetching a window of multi-modal data (like images, actions) around each event’s timestamp.
The EventDataModule is a PyTorch Lightning DataModule that simplifies the use of EventDataset, handling data loading, splitting, and batching.
Basic Information#
Here are the key arguments for configuring EventDataModule and its underlying EventDataset:
Parameters for data_params dictionary within EventDataModule:
Parameter |
Description |
Default (if applicable) |
|---|---|---|
|
List of strings. Paths to dataset directories. These directories should contain both the modal data (e.g., images, actions in LMDBs) and the event LMDB databases. |
N/A (Required) |
|
List of |
N/A (Required) |
|
String. A regular expression used to filter and select specific events from the event database (e.g., |
N/A (Required) |
|
Integer. The length of the data window (number of frames) to retrieve, centered around or offset from each selected event. |
|
|
Integer. An offset (in frames) from the event’s timestamp. The data window starts at |
|
|
String. Specifies the dataset split: |
|
|
Float. The proportion of identified event items to allocate to the training set. The rest go to the validation set. |
|
|
Integer. Random seed used for shuffling items before splitting, ensuring reproducible train/val splits. |
|
|
Boolean. If |
|
|
Optional Integer. Passed to the underlying |
|
|
Optional Integer. Passed to the underlying |
|
Arguments for EventDataModule constructor itself:
Argument |
Description |
Default (if applicable) |
|---|---|---|
|
Dictionary. Contains the parameters listed in the table above for the |
N/A (Required) |
|
Integer. Number of event-centered samples per batch. |
|
|
Integer. Number of subprocesses to use for data loading. |
|
|
Optional Integer. Number of batches loaded in advance by each worker. |
PyTorch default ( |
Hint
event_regex allows you to filter events based on regular expressions. Here are some examples:
(minecraft.kill_entity:.*)|(minecraft.mine_block:.*)|(minecraft.craft_item:.*)|(minecraft.use_item:.*)|(^minecraft\.custom:(?!.*(?:time|one_cm|jump|minute|damage_taken|drop)).*$)(Common game interactions)(minecraft.kill_entity:.*)|(minecraft.craft_item:.*)|(minecraft.pickup_item:.*)|(minecraft.mine_block:.*log)(Interactions involving logs)minecraft.mine_block:minecraft:diamond_ore(Specifically mining diamond ore)
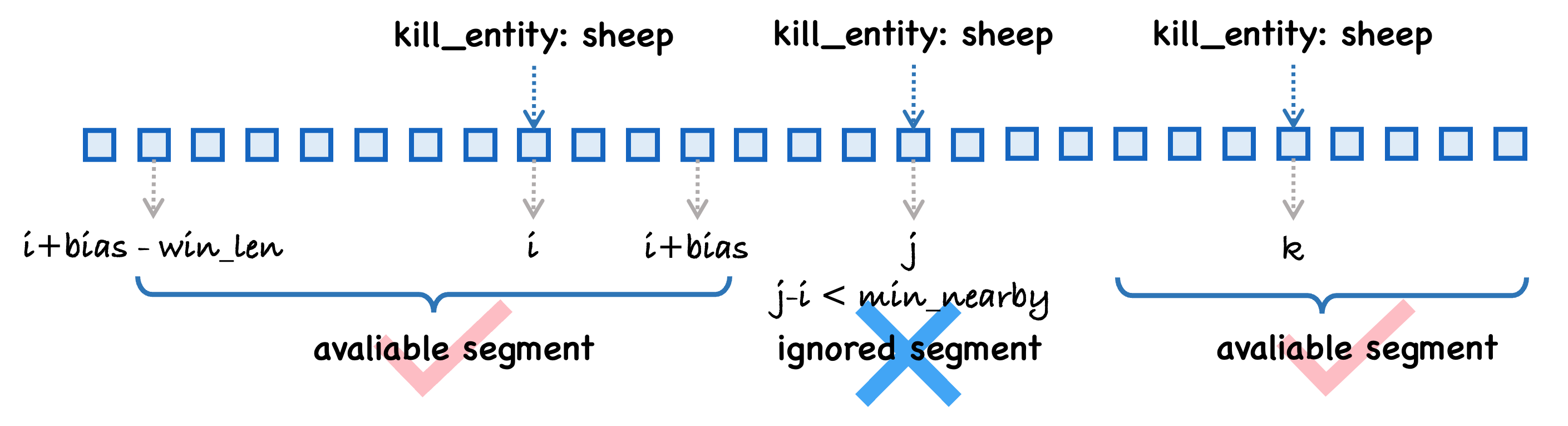
The win_len and bias arguments determine the segment of data extracted around an event. For example, if an event occurs at frame T, bias = -16, and win_len = 32, the data segment will span frames [T-16, T-15, ..., T+15].
Basic Usage#
Here’s an example of how to set up and use EventDataModule to load event-triggered data:
from minestudio.data import EventDataModule
from minestudio.data.minecraft.callbacks import (
ImageKernelCallback,
ActionKernelCallback,
MetaInfoKernelCallback
# Add other necessary callbacks for the modalities you need
)
# 1. Define Modal Kernel Callbacks for desired data modalities
modal_callbacks = [
ImageKernelCallback(frame_width=224, frame_height=224), # For visual frames
ActionKernelCallback(), # For player actions
MetaInfoKernelCallback() # For game metadata
]
# 2. Configure and instantiate EventDataModule
event_data_module = EventDataModule(
data_params=dict(
dataset_dirs=['/nfs-shared-2/data/contractors/dataset_6xx'], # Replace with your dataset path(s)
modal_kernel_callbacks=modal_callbacks,
event_regex='minecraft.mine_block:.*log.*', # Example: find events of mining any log
win_len=64, # Load a window of 64 frames
bias=-32, # Center the window around the event frame
split_ratio=0.9,
verbose=True,
# min_nearby=200, # Optional: filter out events closer than 200 ticks
# max_within=1000 # Optional: limit to 1000 items per event type
),
batch_size=16,
num_workers=4
)
# 3. Setup DataModule (this prepares the EventDataset)
event_data_module.setup()
# 4. Get the DataLoader
train_loader = event_data_module.train_dataloader()
# 5. Iterate through the DataLoader
print("Iterating through event-based batches...")
for i, batch in enumerate(train_loader):
print(f"Batch {i+1} keys: {batch.keys()}")
if 'image' in batch:
print(f" Image batch shape: {batch['image'].shape}")
if 'action' in batch and isinstance(batch['action'], dict): # Action is often a dict of tensors
print(f" Action keys: {batch['action'].keys()}")
if 'text' in batch: # 'text' usually carries the event string
print(f" Example event text: {batch['text'][0]}")
# Add your model training or data processing logic here
if i >= 2: # Print info for a few batches then stop for this example
break
Using with Lightning Fabric for Distributed Training#
EventDataModule can be used with PyTorch Lightning Fabric for distributed training. Fabric will handle the distributed sampler setup.
import lightning as L
from tqdm import tqdm # Optional, for progress bars
from minestudio.data import EventDataModule
from minestudio.data.minecraft.callbacks import (
ImageKernelCallback, ActionKernelCallback, SegmentationKernelCallback # Add/remove as needed
)
# 1. Initialize Lightning Fabric
# Adjust accelerator, devices, and strategy according to your hardware and needs
fabric = L.Fabric(accelerator="cuda", devices=2, strategy="ddp")
fabric.launch() # Important for DDP initialization
# 2. Define Modal Kernel Callbacks
modal_callbacks = [
ImageKernelCallback(frame_width=224, frame_height=224, enable_video_aug=False),
ActionKernelCallback(),
SegmentationKernelCallback(frame_width=224, frame_height=224), # Example if segmentation is needed
]
# 3. Configure and instantiate EventDataModule
data_module = EventDataModule(
data_params=dict(
dataset_dirs=[
'/nfs-shared-2/data/contractors-new/dataset_6xx', # Replace with your actual dataset paths
'/nfs-shared-2/data/contractors-new/dataset_7xx',
],
modal_kernel_callbacks=modal_callbacks,
win_len=128,
split_ratio=0.9,
event_regex='minecraft.mine_block:.*log.*', # Example: filter for mining log events
),
batch_size=3, # This will be the batch size per GPU/process
num_workers=2, # Number of workers per GPU/process
prefetch_factor=4 # Optional: for performance tuning
)
# 4. Setup DataModule
data_module.setup() # This prepares the EventDataset internally
# 5. Get the DataLoader for the desired split (e.g., training)
train_loader = data_module.train_dataloader()
# 6. Setup DataLoader with Fabric for distributed training
# Fabric will automatically wrap the DataLoader with a DistributedSampler.
train_loader = fabric.setup_dataloaders(train_loader)
# 7. Iterate through the DataLoader
rank = fabric.local_rank # Get the rank of the current process
print(f"Rank {rank} starting iteration through event-based distributed batches...")
for idx, batch in enumerate(tqdm(train_loader, disable=(rank != 0))): # tqdm only on rank 0
if idx > 5: # Limit printed batches for brevity in this example
break
# Example: Print some info from the batch, specific to your data structure
if 'image' in batch and 'text' in batch:
print(
f"Rank {rank} - Batch {idx+1}: " + "\\t".join(
[f"ImgShape:{img.shape} Event:'{txt}'" for img, txt in zip(batch['image'], batch['text'])]
)
)
else:
print(f"Rank {rank} - Batch {idx+1} loaded. Keys: {batch.keys()}")
In this distributed setup, Lightning Fabric ensures that each process (GPU) gets a unique shard of the data, and the EventDataModule provides the batches accordingly.