
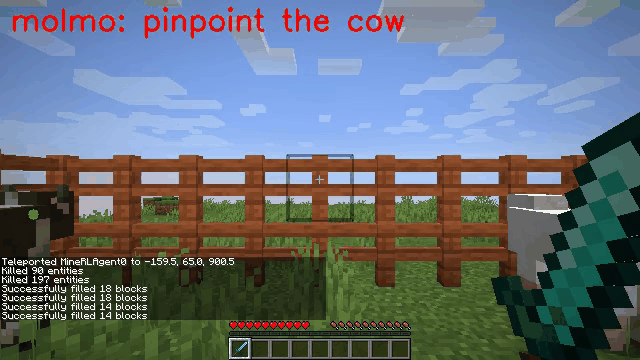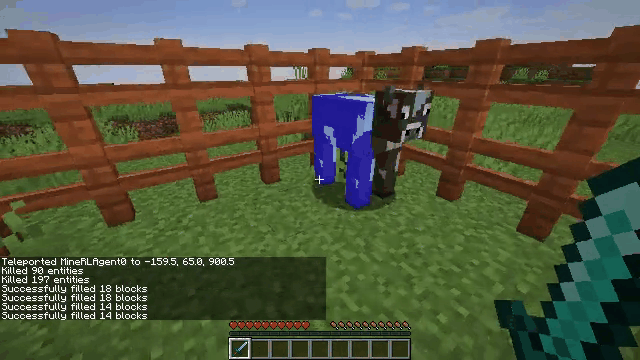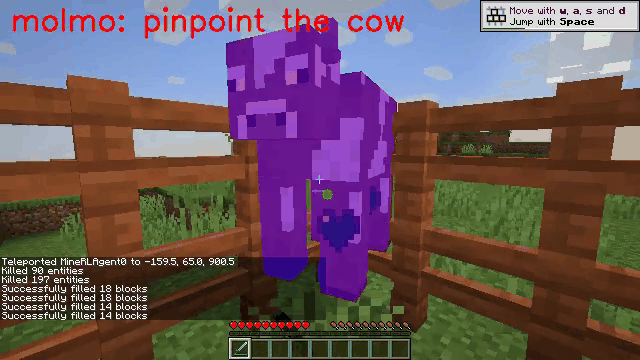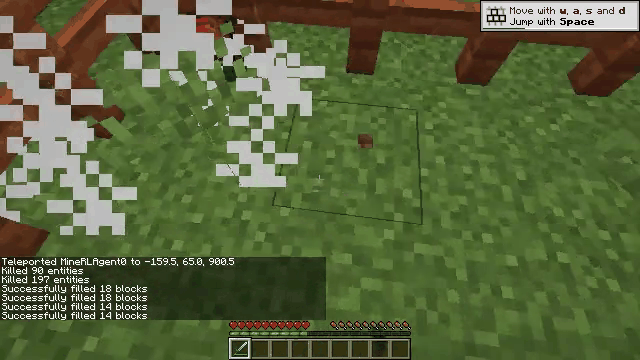
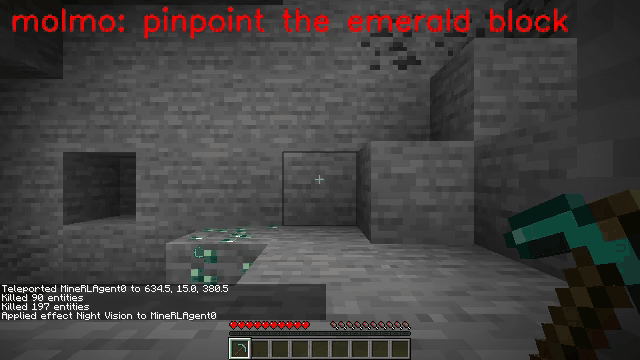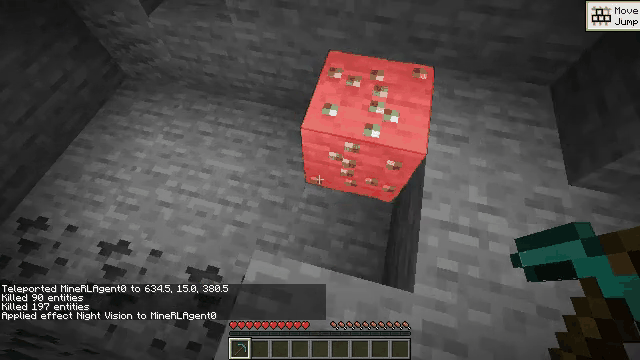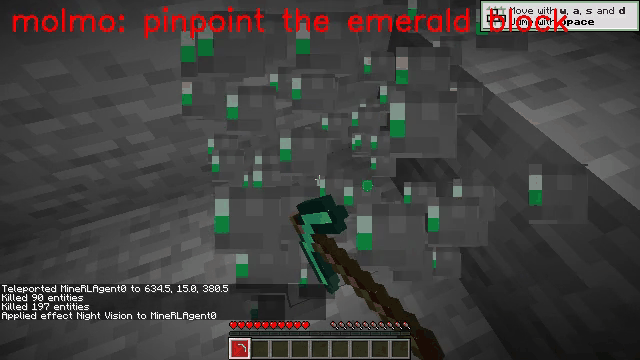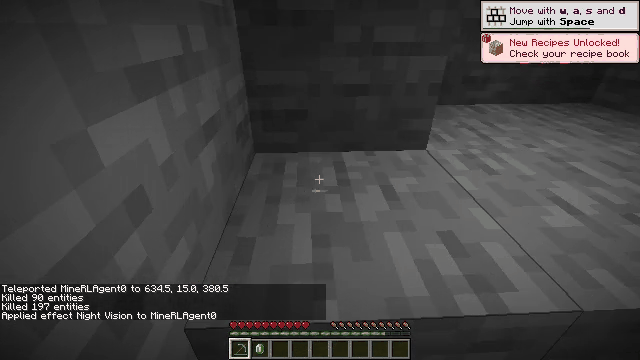
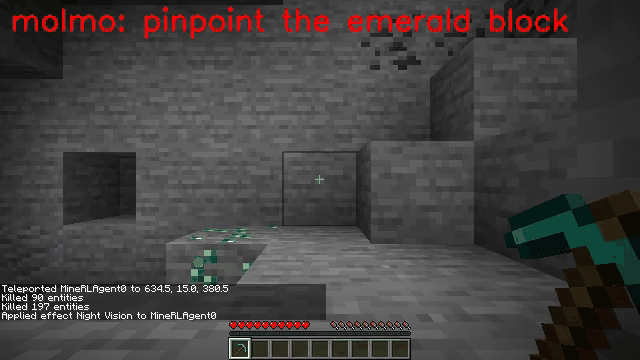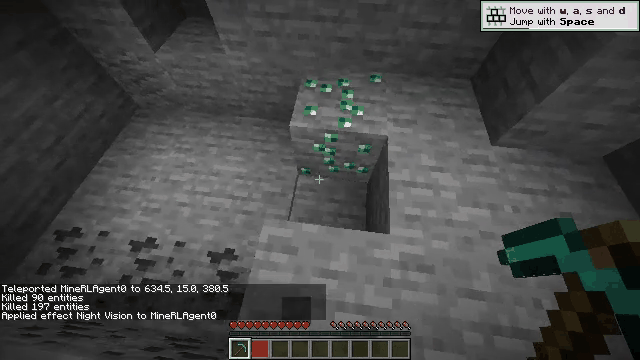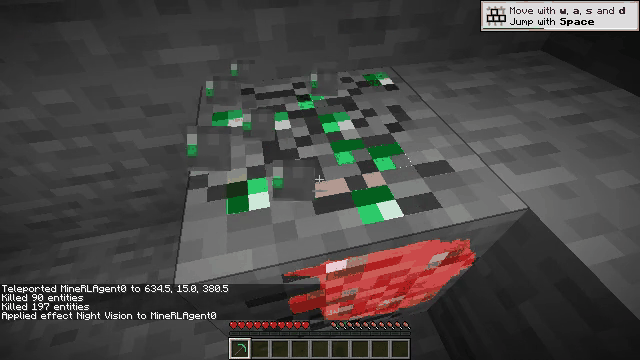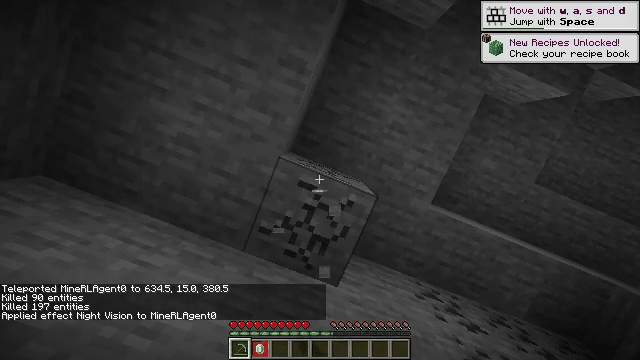
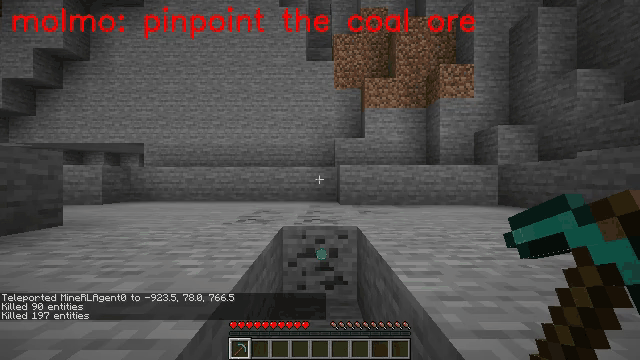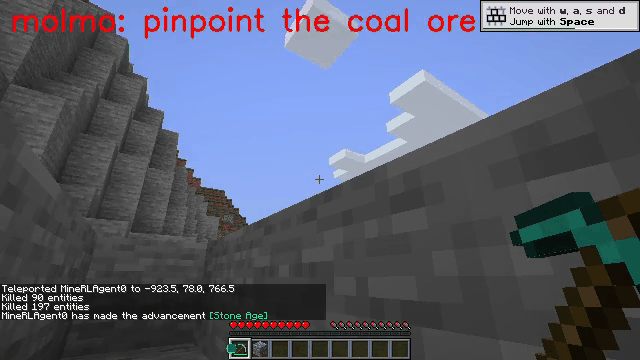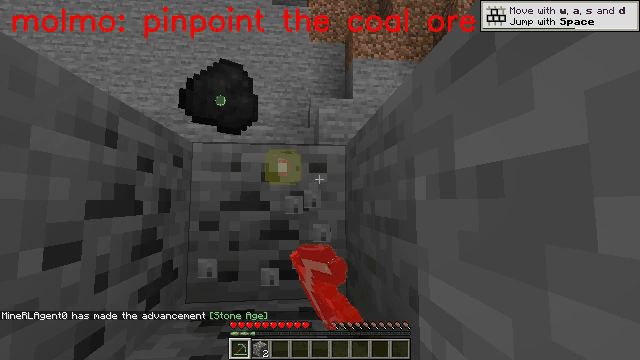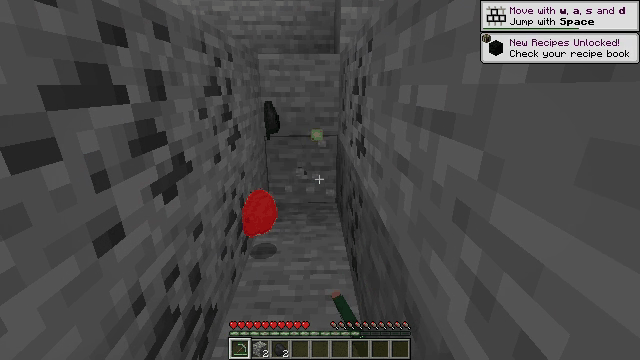
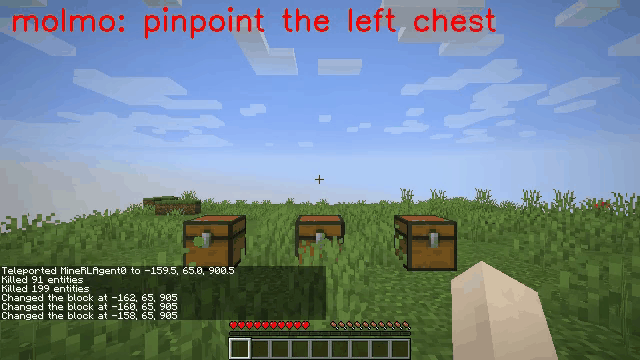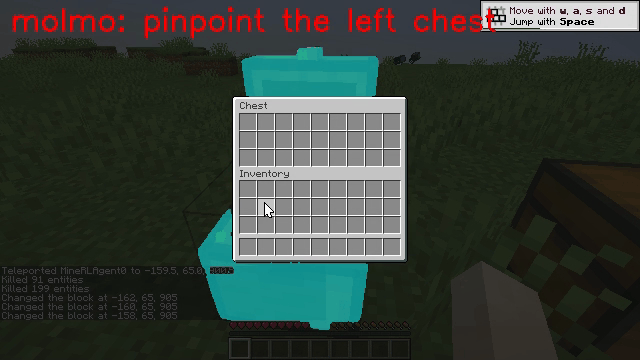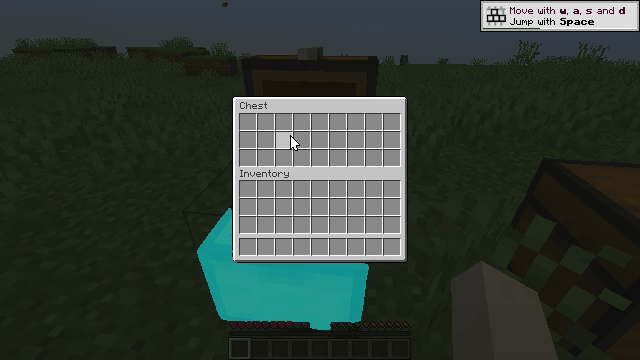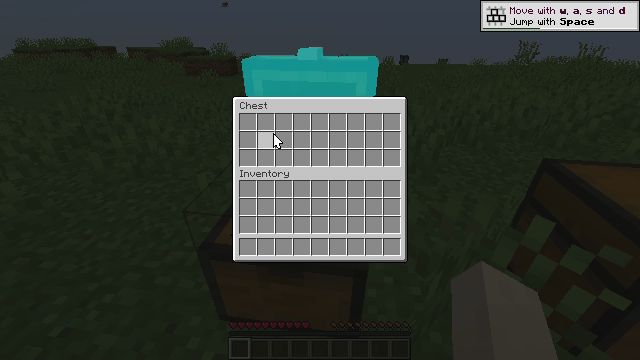
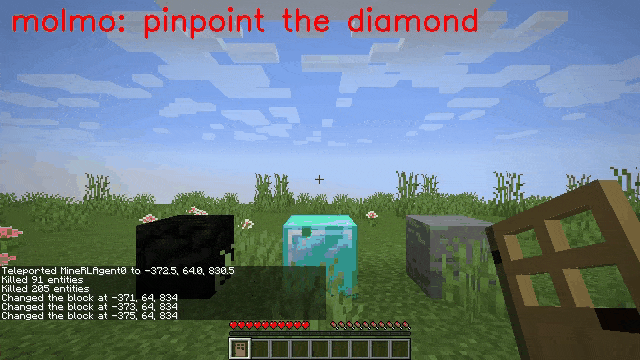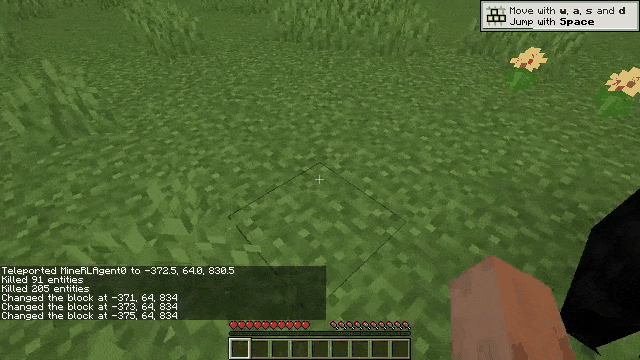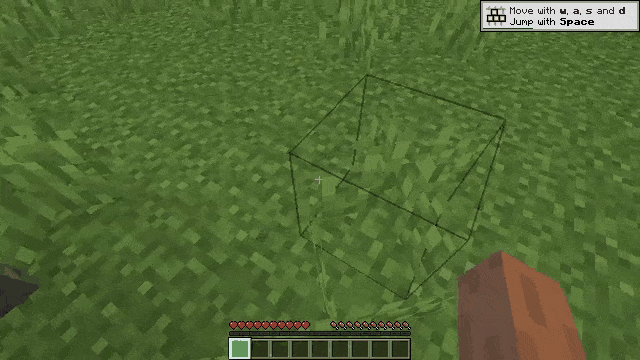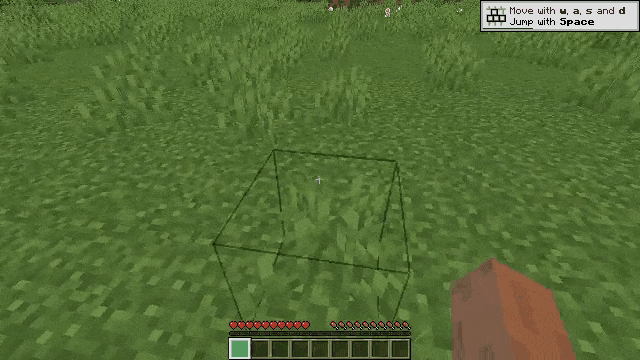
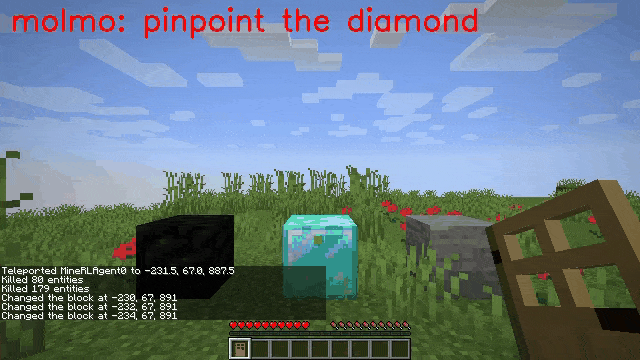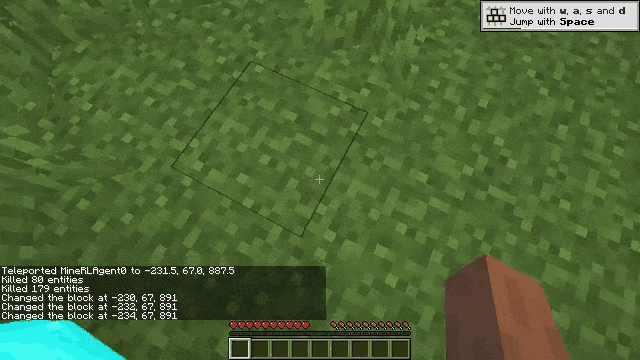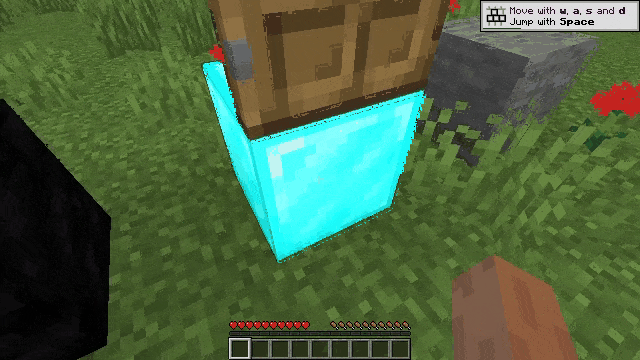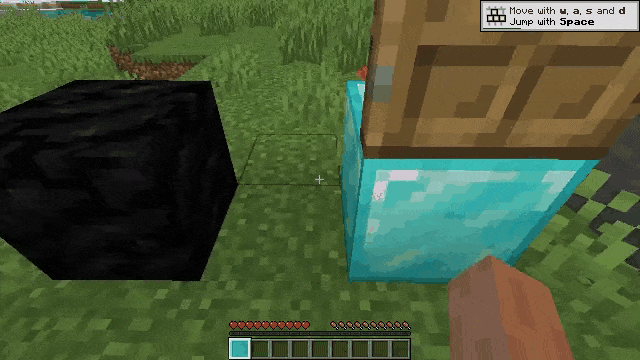
Vision-language models (VLMs) have excelled in multimodal tasks, but adapting them to embodied decision-making in open-world environments presents challenges. One critical issue is bridging the gap between discrete entities in low-level observations and the abstract concepts required for effective planning. A common solution is building hierarchical agents, where VLMs serve as high-level reasoners that break down tasks into executable sub-tasks, typically specified using language. However, language suffers from the inability to communicate detailed spatial information. We propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from past observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, supported by real-time object tracking from SAM-2. Our method unlocks the potential of VLMs, enabling them to tackle complex tasks that demand spatial reasoning. Experiments in Minecraft show that our approach enables agents to achieve previously unattainable tasks, with a 76% absolute improvement in open-world interaction performance.









@article{cai2024rocket1,
title = {ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting},
author = {Shaofei Cai and Zihao Wang and Kewei Lian and Zhancun Mu and Xiaojian Ma and Anji Liu and Yitao Liang},
year = {2024},
journal = {arXiv preprint arXiv: 2410.17856}
}