Preference Goal Tuning: Post-Training as Latent Control for Frozen Policies
Abstract
Goal-conditioned policies enable decision-making models to execute diverse behaviors based on specified goals, yet their downstream performance is often highly sensitive to the choice of instructions or prompts. To bypass the limitations of discrete text prompts, we formulate post-training adaptation as a latent control problem, where the goal embedding serves as a continuous control variable to modulate the behavior of a frozen policy.
We propose Preference Goal Tuning (PGT), a framework that optimizes this latent control variable to align the induced trajectory distribution with task preferences. Unlike standard fine-tuning that updates policy parameters, PGT keeps the policy frozen and updates only the latent goal using a trajectory-level preference objective. This approach essentially searches for the optimal conditioning input that maximizes the likelihood of preferred behaviors while suppressing undesirable ones.
We evaluate PGT on the Minecraft SkillForge benchmark across 17 tasks. With minimal data, PGT achieves average relative improvements of 72.0% and 81.6% on two foundation policies, consistently outperforming expert-crafted prompts. Crucially, by decoupling task alignment (latent goal) from physical dynamics (frozen policy), PGT surpasses full fine-tuning by 13.4% in out-of-distribution settings, demonstrating superior robustness and generalization.
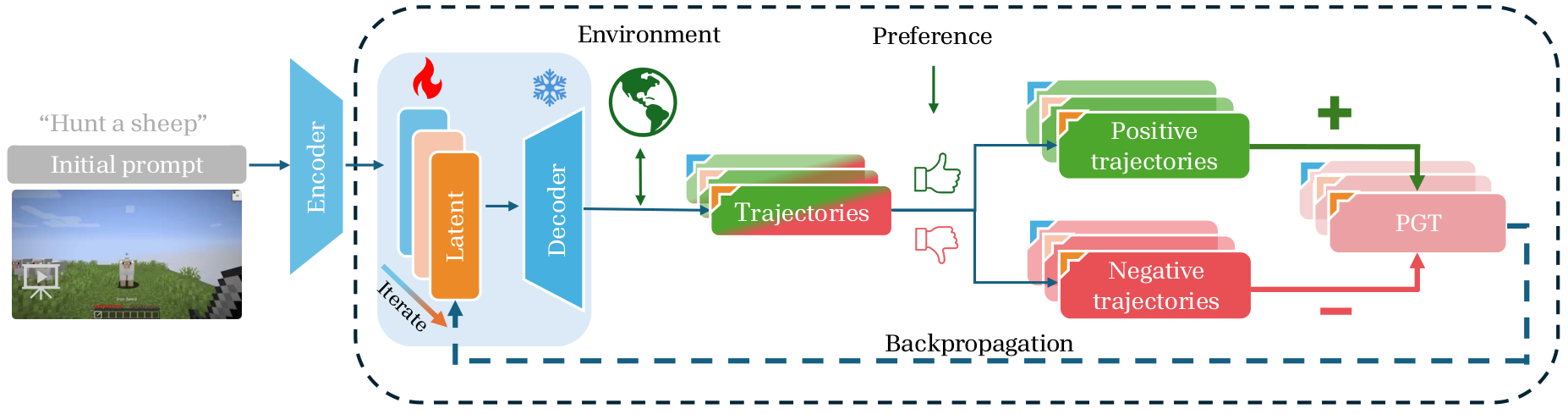
Method Overview
PGT treats the latent goal embedding as the sole adaptation interface. Given a frozen, pre-trained goal-conditioned policy, PGT iterates between collecting trajectories and applying preference-based optimization to shift the latent goal toward preferred behaviors.
Results
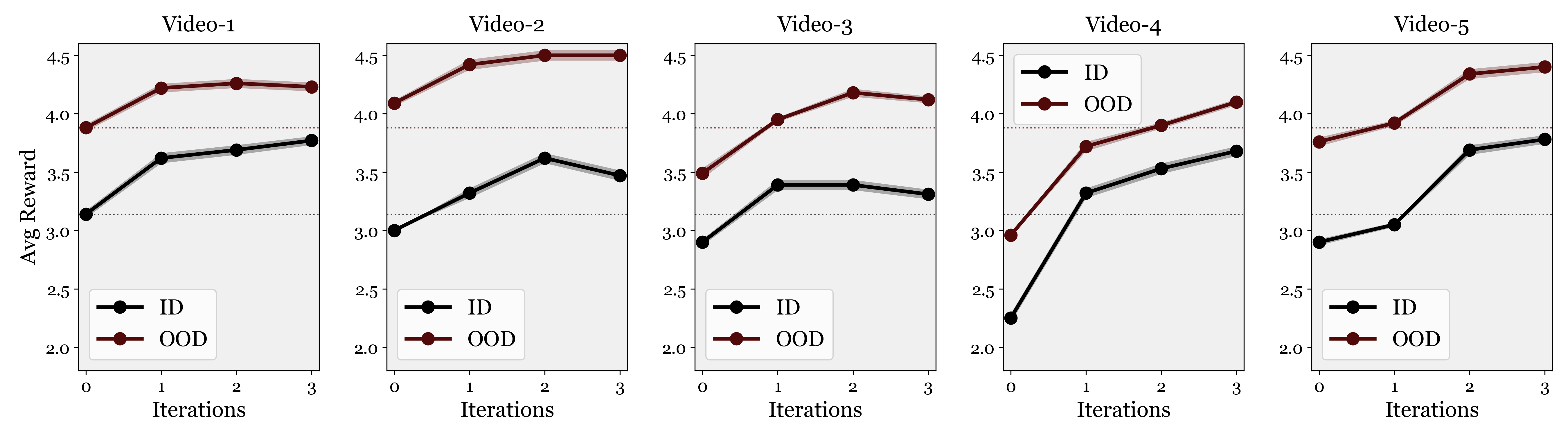
Beyond Prompt Engineering
PGT consistently improves performance regardless of the initial prompt quality. Even prompts that already yield strong baselines are further improved by preference-based latent goal optimization.
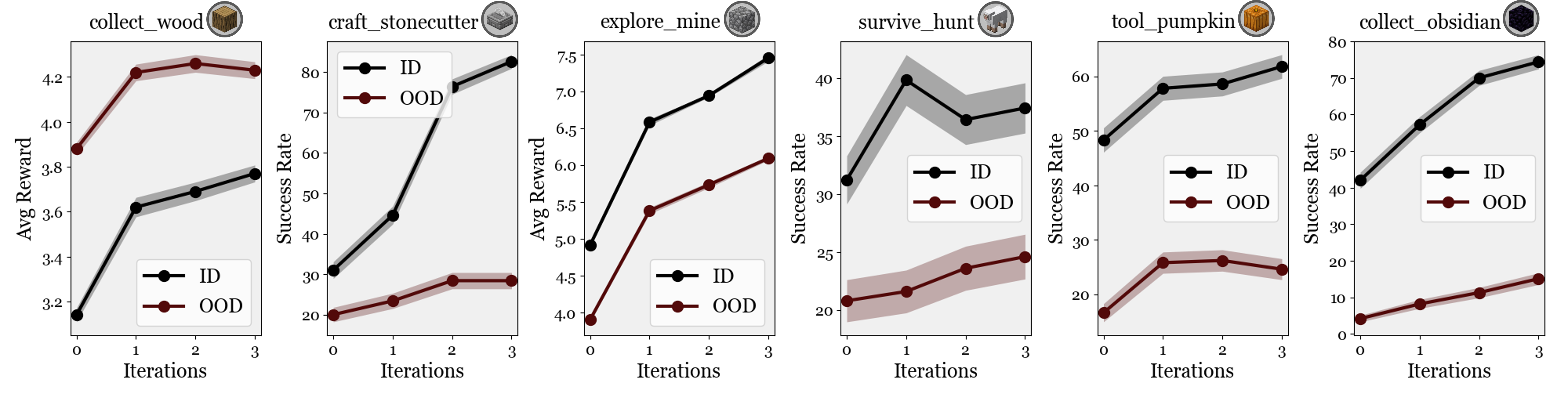
Iterative Refinement
PGT supports iterative data collection and goal refinement, with performance improving steadily across rounds.
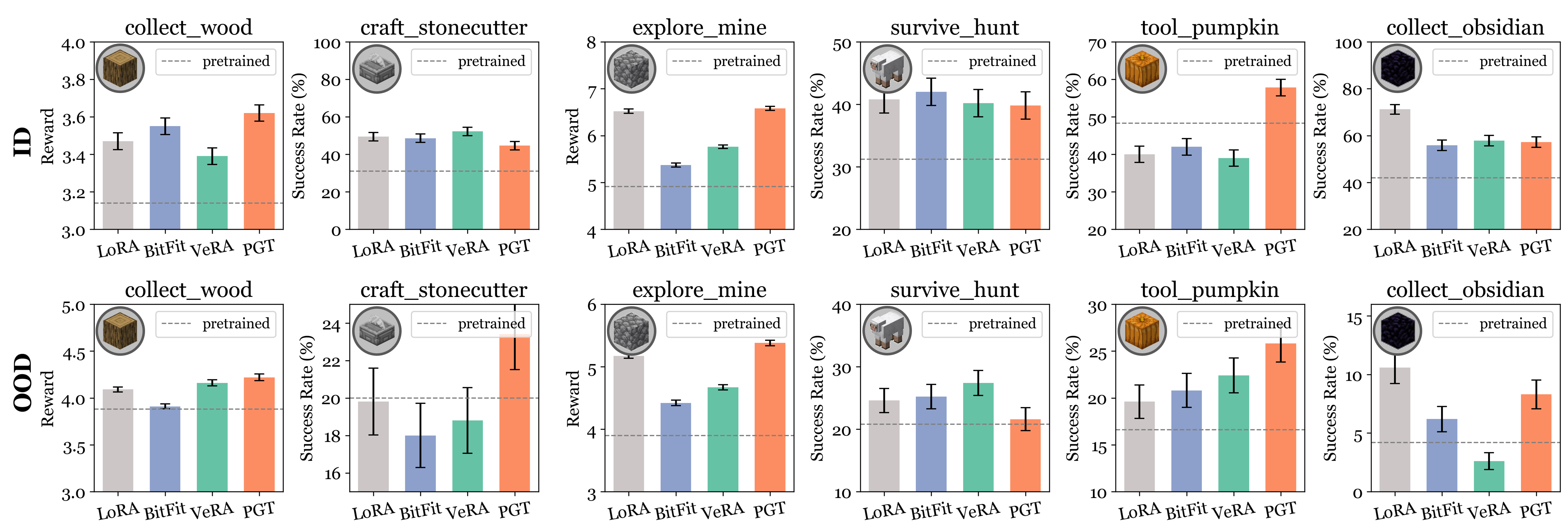
vs. Parameter-Efficient Fine-Tuning
Compared to LoRA, BitFit, and VeRA — which all modify policy parameters — PGT achieves competitive or superior performance under both in-distribution and out-of-distribution settings, with a significantly smaller optimization target.
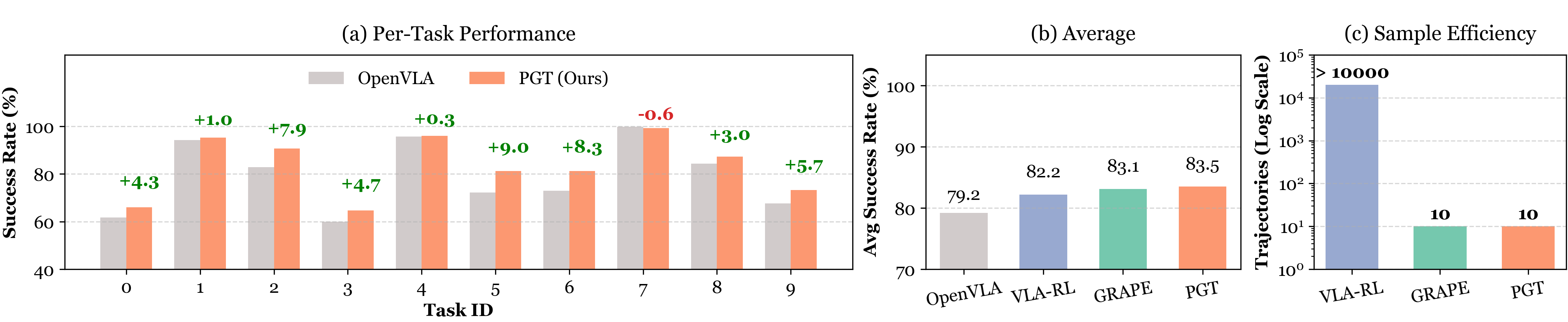
Cross-Domain: Robotic Manipulation
Beyond Minecraft, PGT generalizes to robotic manipulation. Applied to OpenVLA on the LIBERO-goal benchmark, PGT achieves higher performance and sample efficiency than PPO-based VLA-RL, while matching GRAPE with a much simpler preference-ranking function.
Continual Learning Without Forgetting
Conventional continual learning methods update shared policy parameters across tasks, requiring explicit mechanisms (replay buffers, regularization, knowledge distillation) to combat catastrophic forgetting. PGT sidesteps this problem entirely: each task is represented by a single compact latent vector, and the policy backbone is never modified. There is no parameter interference — by design.
Tasks are learned sequentially without revisiting earlier data, in the order: collect_obsidian → tool_pumpkin → craft_crafting_table → explore_climb. After learning all four tasks, PGT is compared against standard continual learning baselines that all fine-tune the full policy: Naive Continual Learning (NCL), Knowledge Distillation (KD), Experience Replay (ER), and Elastic Weight Consolidation (EWC).
| Task | In-Distribution (ID) | Out-of-Distribution (OOD) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ER | EWC | KD | NCL | PGT (Ours) | ER | EWC | KD | NCL | PGT (Ours) | |
| collect_obsidian | 60.2 | 64.6 | 66.8 | 61.2 | 57.2 | 6.0 | 5.4 | 5.4 | 6.8 | 8.2 |
| tool_pumpkin | 65.4 | 60.0 | 60.8 | 61.4 | 57.8 | 25.0 | 23.8 | 20.6 | 20.4 | 25.8 |
| craft_crafting_table | 8.6 | 6.8 | 6.8 | 7.2 | 14.6 | 9.0 | 7.4 | 5.8 | 7.0 | 18.4 |
BibTeX
@misc{zhao2026pgt,
title={Preference Goal Tuning: Post-Training as Latent Control for Frozen Policies},
author={Guangyu Zhao and Kewei Lian and Haoxuan Ru and Borong Zhang and Haowei Lin
and Zhancun Mu and Haobo Fu and Qiang Fu and Shaofei Cai and Zihao Wang
and Yitao Liang},
year={2026},
eprint={2412.02125},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2412.02125}
}